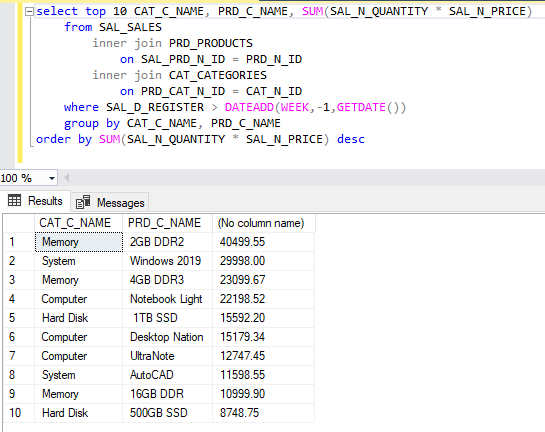
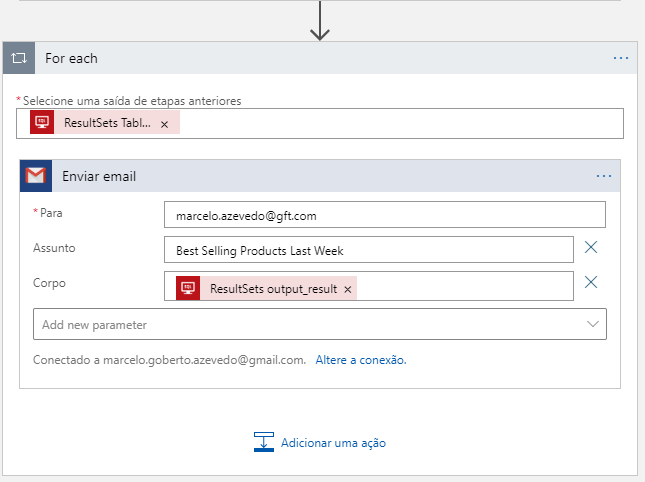
E é nesta solução desse problema que se encaixa perfeitamente um MDM, Master Data Management, em tradução livre ficaria, Gerenciamento de Dados Mestres. Essa solução fornecerá todos os requisitos mencionados anteriormente, como também a consolidação da oferta de dados em uma única fonte, que ofertará os benefícios:
Qualidade dos Dados
No processo de coleta dos dados para transferência para o MDM é possível garantir através de regras de aceitação e da eliminação de dados inválidos. Como resultado os usuários poderão trabalhar com dados consistentes, uniformes e de melhor qualidade, o que tornará os processos de negócios mais eficientes e confiáveis.
Duplicação de Dados
Eliminando qualquer chance de conter dados duplicados, o que nos cenários atuais sem a centralização de dados é extremamente comum e leva a dúvidas em relação qual dados é mais confiável, o MDM irá construir uma única fonte de dados altamente confiável e proverá aumento na eficiência do negócio.
Precisão dos Dados
Sem dados inválidos ou duplicados, as discrepâncias no dados não existiram e aumentaram o nível de precisão dos mesmos, reduzindo os riscos de processamento de informações incorretas, como também o fator de normalização das estrutura facilitando a recuperação e entendimentos dos dados.
Redução de Custos
Uma vez que teremos uma solução gerenciando todos os dados mestres da empresa, automaticamente iremos reduzir os locais que precisam estar processando os dados, monitoramento da utilização, sem contar a eliminação do impacto negativo ao negócio quando um dado impreciso é compartilhado.
Conformidade dos Dados Verídicos
Cada dia que passa os regulamentos e as políticas sobre dados estão ficando cada vez mais rígidos, com isso é fundamental que qualquer negócio tenha total controle (gerenciamento) sobre os dados, pois a não conformidade pode acarretar multas pesadas, como regulamentadas pela LGPD. A aplicação de um gerenciamento dos dados diminui as chances de violações de segurança e possibilita a conformidade regulamentar.
Tomada de Decisão em Dados
Já sabemos como as empresas estão aumentando a utilização dos dados para tomadas de decisões, informações incompletas e incorretas possibilitando à administração tomar decisões mal direcionadas que impactam o crescimento da empresa a curto e longo prazo. O simples fato de ter acesso a dados com qualidade, ajudará todos os gestores a desenvolverem estratégias eficazes.
Estamos num bom momento para considerar uma abordagem de MDM para gerenciamento de dados nas empresas. Já existem algumas ferramentas no mercado despontando com maturidade para oferecer um bom pacote de serviços, como também é possível implementar uma solução interna totalmente adaptada para o contexto do negócio. O que eu sei é, o gerenciamento de dados é um caminho inevitável para qualquer organização que queria estar no futuro entregando valores para seus clientes.
Marcelo Goberto de Azevedo
Arquiteto na GFT Brasil